A little about me

I am a computational pathology postdoctoral fellow at the University of Texas MD Anderson Cancer Center. I received my doctorate
in Computational Statistics from the joint doctoral program at San Diego State University and Claremont Graduate University.
My dissertation work focused on designing and implementing multiple Random Forest-based algorithms to solve computational challenges
in autism research. I also received my first Masters degree in Mathematical Statistics from Shiraz University in Iran and my second Masters in
Biostatistics from San Diego State University.
My research interests include Machine Learning, Data Mining, and Spatial Analysis. Currently, I
am working on developing a spatial pipeline to analyze CODEX images on Glioblastoma.
Research Projects
Matching Methods for Observational Data With Small Group Sizes
Research Question: Which matching algorithm should we use to obtain desired balance between two groups
while maintaining enough subjects in each group?
In the observational studies, matching is used to optimize balance and sample size. Although many matching
algorithms can achieve this goal, in some fields, matching could face its own challenges. Datasets with
small sample sizes and limited numbers of control reservoir are prone to this issue. This problem may
arise in many ongoing research studies, including those in autism spectrum disorders (ASDs). In this
project, we are interested in eliminating the effect of undesirable variables using two types of
algorithms, 1:k nearest matching and full matching.
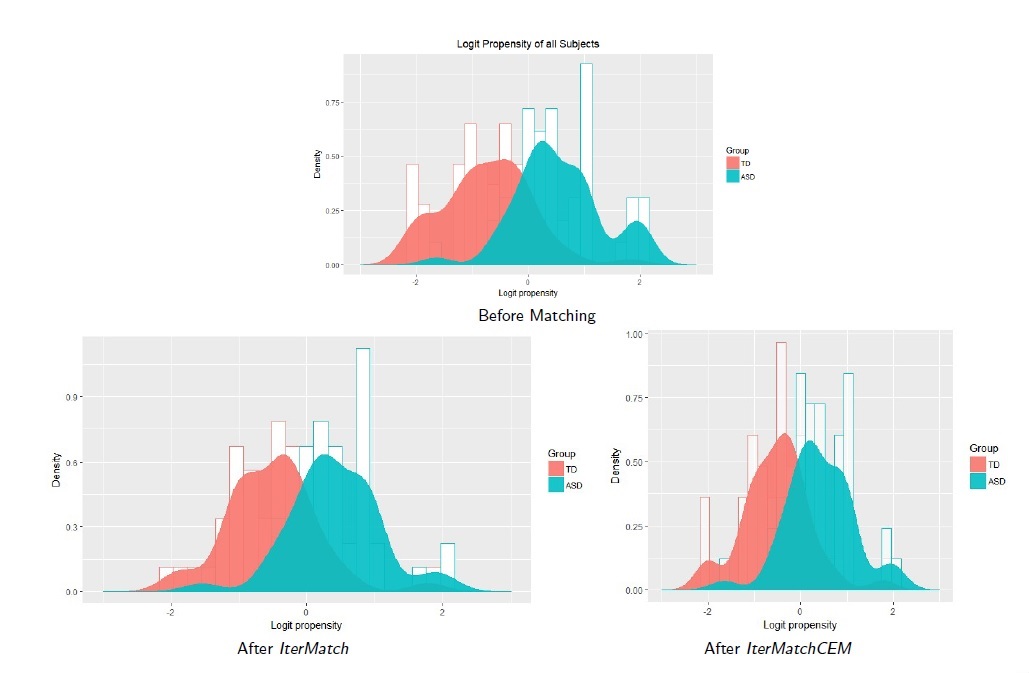 "IterMatch", Statistical R Package for Multivariate Matching Problems
"IterMatch", Statistical R Package for Multivariate Matching Problems
Research Question: How to optimally match two groups of participants on multiple variables with missing data?
Matching two groups on multiple confounding variables is one of the primary steps in conducting observational studies.
All existing matching algorithms can function only with a complete dataset, while none can function with missing data.
Datasets with these problems must impute or only complete cases can be considered in matching. Losing data because of
the limitations in a matching algorithm can decrease the power of the study as well as omit important information.
In this project, we introduce the R package iterMatch that tackles these shortcomings. This package finds a one-to-one
subsample of the data that is balanced on all matching variables while incorporating missing values in an iterative manner.
Random forest is used as a crucial tool to handle missing values when constructing a distance matrix to be fitted to an
optimal matching algorithm. We measure the robustness of the matching results by injecting levels of missing values across
two medium and large datasets for comparison. More detail is provided in this chapter.
 Mixed-Effects Random Forest-based Classification Algorithms for Clustered Data
Mixed-Effects Random Forest-based Classification Algorithms for Clustered Data
Research Question: How to build a high accuracy binary classifier using multi-modal imaging modality with multi-site data?
To date, a variety of classification schemes have been proposed, and the accuracy of classification has reached as high as 95
percent for many disorders, including Autism Spectrum Disorder (ASD). However, to build a reliable and robust classification model
for ASD, it is necessary to incorporate a large dataset which is often obtained from multi-site imaging data. In addition to the
extended sample size, including multiple MRI modalities can increase the coherency of the brain picture. However, two challenges
are associated with an extended sample size and multi-modal dataset. The first issue is controlling the source of variation that
is imposed by multiple imaging sites. Second, it is necessary to use a dimensional reduction algorithm to cope with the computational
complexity of multi-modal data. Controlling the multi-site variability is particularly important as it can be mixed with the
heterogeneous nature of ASD to build a robust and accurate classification model.
We addressed both concerns by proposing two mixed-effects random forest-based classification algorithms, applicable to multi-site
(clustered) data using rs-fMRI and structural MRI (sMRI) modalities. These algorithms control the random effects of the confounding
factor of the imaging site. Additionally, the algorithms internally control the fixed effect of the phenotypic variables such as age
while building classification model. Moreover, they eliminate the necessity of utilizing a separate dimension reduction algorithm for
high-dimensional data such as functional connectivity in a non-linear fashion.
 Diagnostic Classification of ASD Using Multimodal Imaging Data
Diagnostic Classification of ASD Using Multimodal Imaging Data
Research Question: Which imaging modality is more informative when compared to others in classification of ASD?
Despite the numerous studies conducted with different neuroimaging modalities applied to the diagnostic classification of autism spectrum
disorders (ASDs) by use of machine learning algorithms, none have assessed whether one MRI modality may be more informative compared to
others. In this study, conditional random forest (CRF) was applied to structural (anatomical) MRI, diffusion tensor imaging
(DTI), and functional connectivity MRI (fcMRI) data to assess which modality may be more or less informative.
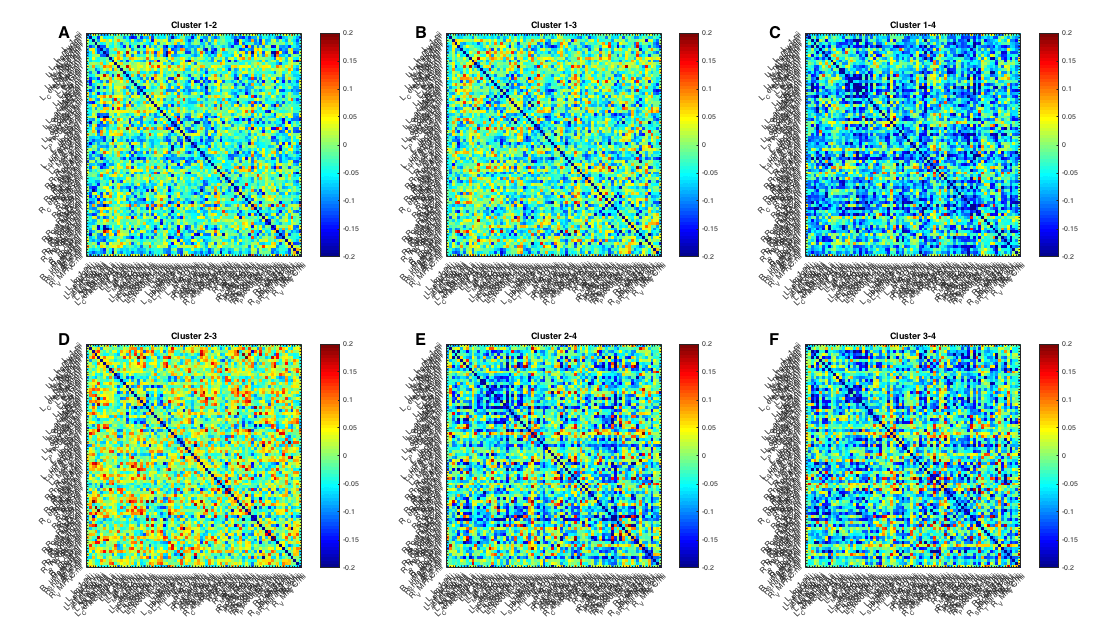
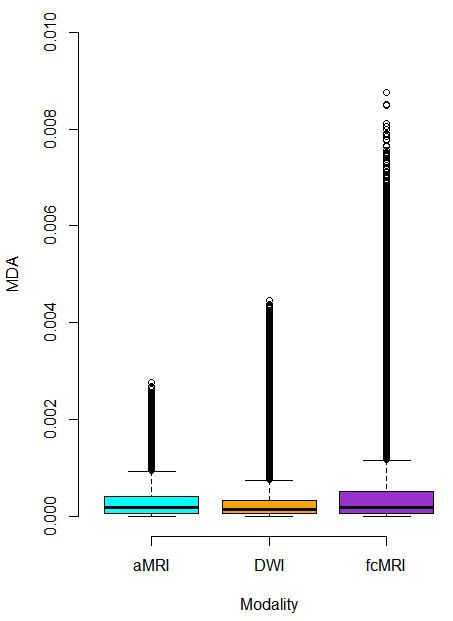 Potential Subtyping Using Behavioral Measurements
Potential Subtyping Using Behavioral Measurements
Can subtyping ASD participants based on behavioral and diagnostic measures reveal distinct resting state functional connectivity
(rs-fc) patterns?
ASDs are characterized by great heterogeneity of symptoms, likely secondary to multiple etiological subtypes of ASDs. Few studies
have directly focused on imaging data with the goal of characterizing subtypes of ASDs, but in the study performed by Theo behavioral
and neuropsychological data are used with unsupervised machine learning to characterize potential subtypes of ASDs. We are
investigating whether different subtypes based on the behavioral data are linked to different resting state functional connectivity profiles.
Publication
Google Scholar.
Contact
Elements
Text
This is bold and this is strong. This is italic and this is emphasized.
This is superscript text and this is subscript text.
This is underlined and this is code: for (;;) { ... }. Finally, this is a link.
Heading Level 2
Heading Level 3
Heading Level 4
Heading Level 5
Heading Level 6
Blockquote
Fringilla nisl. Donec accumsan interdum nisi, quis tincidunt felis sagittis eget tempus euismod. Vestibulum ante ipsum primis in faucibus vestibulum. Blandit adipiscing eu felis iaculis volutpat ac adipiscing accumsan faucibus. Vestibulum ante ipsum primis in faucibus lorem ipsum dolor sit amet nullam adipiscing eu felis.
Preformatted
i = 0;
while (!deck.isInOrder()) {
print 'Iteration ' + i;
deck.shuffle();
i++;
}
print 'It took ' + i + ' iterations to sort the deck.';
Lists
Unordered
- Dolor pulvinar etiam.
- Sagittis adipiscing.
- Felis enim feugiat.
Alternate
- Dolor pulvinar etiam.
- Sagittis adipiscing.
- Felis enim feugiat.
Ordered
- Dolor pulvinar etiam.
- Etiam vel felis viverra.
- Felis enim feugiat.
- Dolor pulvinar etiam.
- Etiam vel felis lorem.
- Felis enim et feugiat.
Icons
Actions
Table
Default
| Name |
Description |
Price |
| Item One |
Ante turpis integer aliquet porttitor. |
29.99 |
| Item Two |
Vis ac commodo adipiscing arcu aliquet. |
19.99 |
| Item Three |
Morbi faucibus arcu accumsan lorem. |
29.99 |
| Item Four |
Vitae integer tempus condimentum. |
19.99 |
| Item Five |
Ante turpis integer aliquet porttitor. |
29.99 |
|
100.00 |
Alternate
| Name |
Description |
Price |
| Item One |
Ante turpis integer aliquet porttitor. |
29.99 |
| Item Two |
Vis ac commodo adipiscing arcu aliquet. |
19.99 |
| Item Three |
Morbi faucibus arcu accumsan lorem. |
29.99 |
| Item Four |
Vitae integer tempus condimentum. |
19.99 |
| Item Five |
Ante turpis integer aliquet porttitor. |
29.99 |
|
100.00 |